美國計算科學協會分會
曾獲《語言學期刊》最佳論文獎。 Kim 研究員是 LG
在AI研究院超級智慧實驗室實習期間,他與超級智慧實驗室負責人李文泰等研究人員一起研究生成式AI(人工智慧)。
我們開發了「BIGGEN BenchMARK」來評估模型的效能。金所長領導的研究團隊包括延世大學和麻省理工學院的研究人員。
麻省理工學院等多所大學的研究人員參與了這項研究。現有的生成式人工智慧模型評估方法依賴於靈活性、無害性等抽象指標,其結果可能與人類所獲得的結果有所不同。
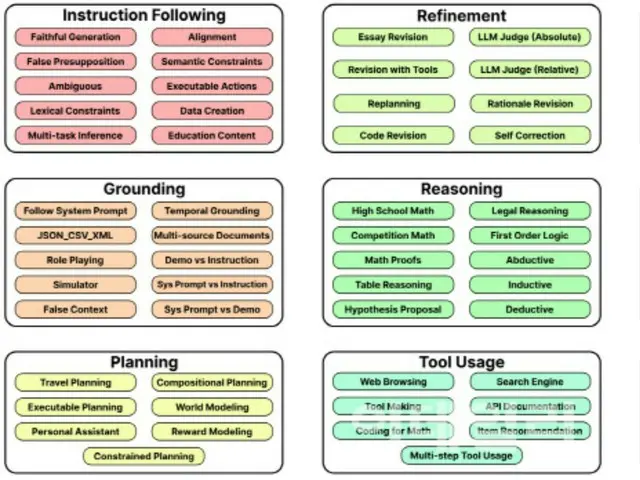
確實存在這樣的情況。同時,BigGen BenchMARK將AI模型應具備的能力分為九種類型,例如執行指令的能力、進行邏輯推理的能力、理解多樣化語言和文化背景的能力。 77
它由 765 個項目組成,用於評估技能的表現。 LG AI 研究所使用 BigGen 基準測試評估了 103 個生成式 AI 模型,並與一組專家進行了交叉驗證。
證據顯示其具有高度的有效性。
2025/05/02 09:24 KST
Copyrights(C) Edaily wowkorea.jp 101